On these few months, I’m focusing on doing a Go project. Instead of working on a project, I also have some Go projects to maintain, so I’m using GVM to manage multiple versions of Go. Besides using the multiple versions, I also separated pkgsets between the projects. About how to manage the versions and pkgsets, we can read the introduction here.
GVM is easy to use. I usually use these commands below when working on Go project.
List all available versions
$ gvm listallList installed versions
$ gvm listInstall specific version
$ gvm install <go-specific-version>Create pkgset
$ gvm use <go-specific-version>
$ gvm pkgset create <pkgset-name>Switch to specific pkgset
$ gvm use <go-specific-version>
$ gvm pkgset use <pkgset-name>Actually GVM is very easy to use. We can switch between the versions or pkgsets installed on the laptop. But, there is one thing that disturb me. I’m used to using virtualenvwrapper when doing a Python project. The thing is, I can easily switch to the environment with one line of command.
Creating project environment
$ mkvirtualenv -p python3.10 my-projectSwitch the environment
$ workon my-projectYes, I can switch to the specific environment without selecting the python version first. The autocomplete also works great.

Unlike virtualenvwrapper, on gvm, we have to select the version first, then we can select the pkgset we want to working on. Then, I think I have to find virtualenvwrapper like for GVM version, to easily create and select the pkgset. Unfortunately, I cannot find any tools or library that can fulfill my purpose, so it’s time to invent the wheel.
CREATING USE-GVM AND CREATE-GVM COMMAND
To simplify the commands, I created 2 scripts to create and switch the version managers and pkgsets.
use-gvm.sh
#!/bin/bash
help() {
echo -e "$0 helps you easily to switch to existing go version and pkgset." && \
echo -e "Usage: $0 <pkgSetName>|<goVersion>" && \
echo -e "Example: $0 elastic-go|go1.21.4"
}
# check gvm root variable
if [[ "$GVM_ROOT" == "" ]];
then echo "Please set GVM_ROOT environment!" && exit
fi
if [ -z "$1" ];
then help && exit
fi
PKGSET_DIR=$GVM_ROOT/pkgsets
TEMP_ARGS=${1//\// }
ARGS=(${TEMP_ARGS})
# check go version
GO_VERSION=${ARGS[1]}
GO_VERSION_DIR=$PKGSET_DIR/$GO_VERSION
if test ! -d $GO_VERSION_DIR
then echo -e "go version not exist!" && exit
fi
# check go version
GO_PKGSET=${ARGS[0]}
FULL_PKGSET_DIR=$GO_VERSION_DIR/$GO_PKGSET
if test ! -d $FULL_PKGSET_DIR
then echo "pkgset not exist!" && exit
fi
# load gvm scripts to detect subcommand
source $GVM_ROOT/scripts/gvm
gvm use $GO_VERSION && gvm pkgset use $GO_PKGSETcreate-gvm.sh
#!/bin/bash
help() {
echo "$0 helps you create a pkgset in one line"
echo -e "Usage: $0 -n <pkgSetName> -g <goVersion>" && \
echo -e "Example: $0 -n elastic-go -g go1.21.4"
}
# check gvm root variable
if [[ "$GVM_ROOT" == "" ]];
then echo "Please set GVM_ROOT environment!" && exit
fi
if [ -z "$1" ];
then help && exit
fi
while getopts g:n: flag
do
case "${flag}" in
g) goversion=${OPTARG};;
n) name=${OPTARG};;
esac
done
if [[ $goversion == "" ]];
then echo -e "-g is empty, go version is required!" && exit
fi
if [[ $name == "" ]];
then echo -e "-n is empty, pkgset name is required!" && exit
fi
FULL_GO_VERSION_DIR="$GVM_ROOT/gos/$goversion"
if test ! -d $FULL_GO_VERSION_DIR
then echo -e "cannot find go version, please install it first!" && exit
fi
FULL_PKGSET_DIR="$GVM_ROOT/pkgsets/$goversion/$name"
if test -d $FULL_PKGSET_DIR
then echo -e "pkgset $name is already exist with selected go version!" && exit
fi
# load gvm scripts to detect subcommand
source $GVM_ROOT/scripts/gvm
gvm use $goversion && gvm pkgset create $name && gvm use $goversion && gvm pkgset use $nameuse-gvm.sh is a script to switch between pkgsets, and create-gvm.sh is a script to select version and create pkgset. Then we need to use dot command to implement the environment to the current session. To do that, we have to add alias command to call the original script. We can add these lines to our .bashrc
use-gvm(){
. /usr/local/bin/use-gvm.sh $1
}
create-gvm(){
. /usr/local/bin/create-gvm.sh $@
}For the last step, I created completion script to help the command autocomplete.
easy-gvm-completion.bash
#!/bin/bash
_usegvm_completions()
{
# check gvm root variable
if [[ "$GVM_ROOT" == "" ]];
then echo "Please set GVM_ROOT environment!" && exit
fi
PKGSET_DIR="$GVM_ROOT/pkgsets"
GO_INSTALLED=`ls $GVM_ROOT/gos`
GO_PKGSET_LIST=""
# list go installed
for i in ${GO_INSTALLED// / }
do
# list pkgset installed
PKGSET_INSTALLED_DIR=`ls $PKGSET_DIR/$i`
for j in ${PKGSET_INSTALLED_DIR// / }
do
GO_PKGSET_LIST+="$j/$i "
done
done
COMPREPLY=($(compgen -W "$GO_PKGSET_LIST" "${COMP_WORDS[1]}"))
}
_creategvm_completions()
{
COMPREPLY=()
local cur=${COMP_WORDS[COMP_CWORD]}
local prev=${COMP_WORDS[COMP_CWORD-1]}
opts="-g -n"
if [[ ${cur} == -* ]]
then
COMPREPLY=($(compgen -W "$opts" -- $cur ) )
return 0
fi
# check gvm root variable
if [[ "$GVM_ROOT" == "" ]];
then echo "Please set GVM_ROOT environment!" && exit
fi
GO_INSTALLED=`ls $GVM_ROOT/gos`
# # list go installed
GO_VERSIONS=""
for i in "${GO_INSTALLED// / }"
do
GO_VERSIONS+=$i
done
case "${prev}" in
-g)
COMPREPLY=( $( compgen -W "$GO_VERSIONS" -- $cur ) )
return 0
;;
-n)
return 0
;;
*)
;;
esac
}
complete -F _usegvm_completions use-gvm
complete -F _creategvm_completions create-gvmLoad the completion script in .bashrc
source /path/to/easy-gvm-completion.bashAfter finishing the steps, we can open the new session and try the command. We can also see the suggestion when pressing <tab>

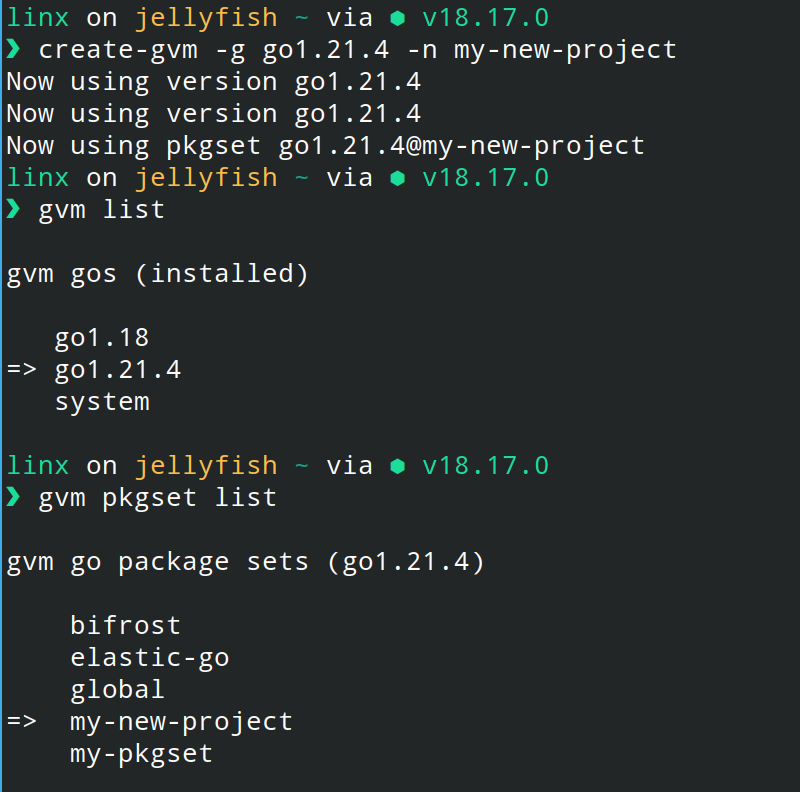
When we want to create pkgset, we will see the suggestion for the go version when using -g flag.

Then, when we create pkgset, it will automatically use the new pkgset.
Conclusion
Actually, this is just for simplifying gvm command, to create and switch the pkgset. So the function is very specific to fulfill my own purpose. There are still so many commands we can create and help us to easier our job. Hopefully this article could have helped you. Thank you! 😀